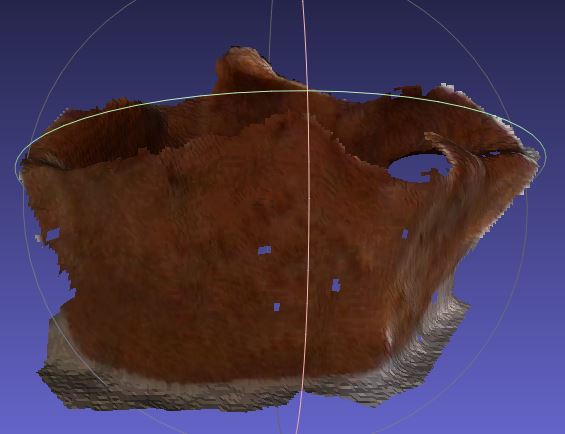
Oh!
A tree stump. I thought it was a mountain.
I actually don’t think it is the large transformation – I think it is having enough overlap in the images
with sufficient correspondence points that are unambiguous.
My continuing battles with ICP have revealed to me just how vulnerable the process is to being misled by “local minima”. So the initial guess transformation is critically important.
I have several hundred overlapping images (1m^2 of surface area for each image). I complete joining them together with ICP, but run an ongoing check on the sanity of the transformation matrix predicted.
I know my initial guesses can only be out by a couple of mm – so anything beyond a couple of degrees of rotation, and 10 mm of translation (total) is rubbish.
So I do a first pass through all the images, and compile a list of translations I don’t trust (they are not concatenated into the image). Then on a second pass, I try to fit the rejected images in . So on the second pass, there are far fewer gaps in the image and the rejected images now have more of a chance, as there are more correspondence points.
Does that make sense?
However, this is not perfect.
But it is better than what I had before.
I have solved many problems. I found the checkerboard I was calibrating the camera with was about 1% out in one dimension. That did not help! When I fixed that, matters improved considerably.
So check your camera calibration is perfect. I had to clip the edges of the image – as the calibration does not really reach all the way to the edge of the lens.
So, I think that if you have sufficient overlapping points, a good guess of the translation matrix to start with, then you can start optimising the threshold value to use. I’ve been looking for answers as to what the units of the threshold value are – but I can only currently guess.
M